如何训练自编码器?(自编码器)
自编码器(Autoencoder)是什么?
自编码器是一种神经网络模型,它学习如何有效地编码输入信息,然后如何重建这些信息以产生输出。它由两部分组成:编码器将输入编码为潜在表示,然后解码器将这个表示解码为输出。

自编码器有哪些应用?
自编码器可以应用于降维、特征学习、去噪、异常检测等任务。在深度学习领域,自编码器被广泛用于预训练模型,为后续的任务提供更好的特征表示。
自编码器的原理是什么?
自编码器的原理是通过最小化重建误差来学习输入数据的潜在表示。在训练过程中,编码器尝试将输入数据压缩为低维表示,然后解码器尝试从这些表示中重建原始输入数据。通过最小化重建误差,自编码器可以学习到输入数据的内在结构和特征。
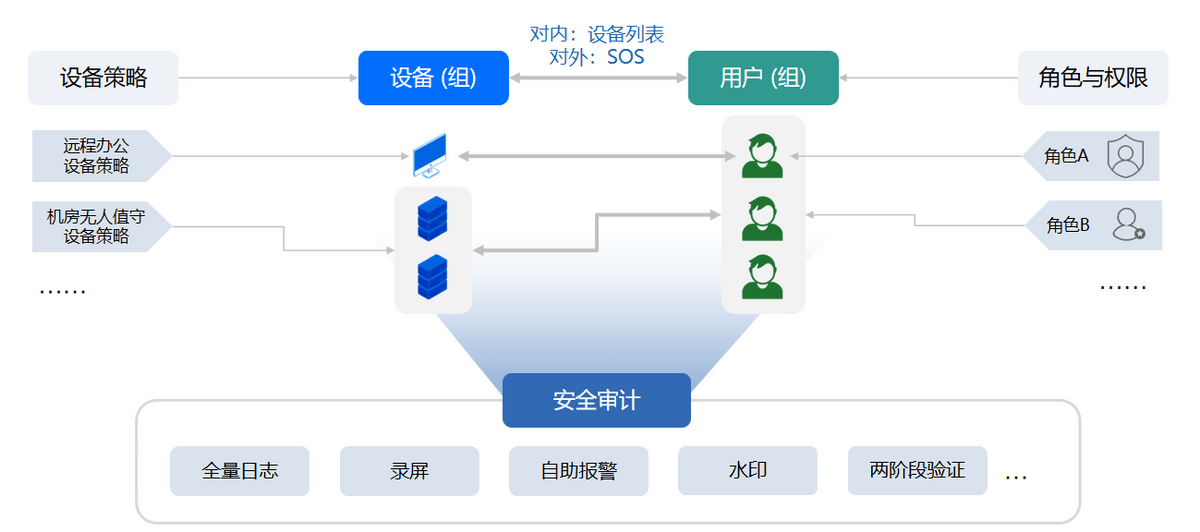
如何训练自编码器?
训练自编码器通常采用反向传播算法和梯度下降优化算法。首先,输入数据被送入编码器,得到潜在表示。然后,解码器使用这些表示来生成输出。接着,计算重建误差并反向传播到编码器和解码器,通过梯度下降优化算法更新网络参数。
自编码器的优缺点是什么?
自编码器的优点包括能够学习到数据的内在结构和特征、能够降维和去噪等。然而,自编码器的缺点包括可能过拟合和缺乏可解释性。此外,对于复杂的非线性数据,自编码器的性能可能不够理想。
如何改进自编码器?
有多种方法可以改进自编码器的性能,例如使用更复杂的网络结构、增加正则化项、使用不同的优化算法等。此外,还可以结合其他技术如生成对抗网络(GAN)等来提高自编码器的性能。
自编码器与其他神经网络模型的区别是什么?
自编码器与其他神经网络模型的区别在于它的目标不是直接预测输出,而是学习输入数据的潜在表示。此外,自编码器是一种无监督学习方法,而其他神经网络模型如全连接神经网络、卷积神经网络等通常是有监督学习方法。
自编码器的参数有哪些?
自编码器的参数包括编码器和解码器的网络结构参数、学习率、正则化参数等。其中,网络结构参数是自编码器的核心参数,它们决定了输入数据如何被压缩和重建。
如何评估自编码器的性能?
评估自编码器的性能通常采用重构误差、特征可视化等方法。重构误差越小,说明自编码器对输入数据的重建能力越强。此外,还可以通过可视化自编码器学习到的特征来评估其性能。
自编码器有哪些变体?
自编码器有许多变体,如卷积自编码器、变分自编码器等。这些变体在保持自编码器的基本原理的同时,针对特定任务进行了改进和优化。
自编码器在实际应用中需要注意哪些问题?
在实际应用中,使用自编码器需要注意过拟合问题、缺乏可解释性等问题。此外,还需要根据具体任务选择合适的网络结构、优化算法和学习率等参数。
自编码器的未来发展方向是什么?
未来,自编码器的研究方向可能包括结合其他技术如生成对抗网络、强化学习等来提高性能和可解释性。此外,随着深度学习技术的不断发展,自编码器可能会在更多领域得到应用。
如何使用Python实现自编码器?
使用Python实现自编码器需要使用深度学习框架如TensorFlow或PyTorch。首先需要定义编码器和解码器的网络结构,然后使用优化算法训练模型。在训练过程中,需要计算重建误差并更新网络参数。